Pepe Silv.AI - Who Wants Me to Know What?
Pepe Silv.AI
Trying to answer the question "Who wants me to know what?"

There's a lot of talk of one-shotting solutions with LLMs, and as someone who has been working with LLMs
since OpenAI sent out a beta invite to all the weirdos who had been signed up for their mailing list
since 2016, I can tell you that even now, years later, we are not there yet. And I'll briefly say that
we will likely never be there until the LLMs themselves can account for every potential use case that
every human may use it for, because as soon as human beings see a boundary, we push against it. That's
how we innovate. Now, that being said, I think that when LLMs are used alongside classic programming,
and the calls to them are treated like any other function call, you can do create some really
interesting and, more importantly, precise, solutions.
A background in Pepe Silv.AI
It all started when I was reading a Verge article in 2023 about GM Batteries. Huh, I thought, I wonder if there's a chance this is actually an ad. I wonder if General Motors and The Verge are owned, or at least influenced by the same bigger company or investor.
Enter Pepe v.0.0.1
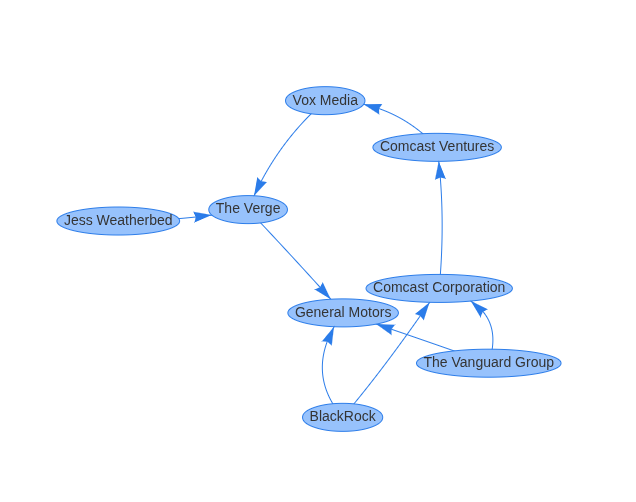
So there's a lot going on here, but I got here by giving ChatGPT the article text, having it extract the entities in the article, including the news site itself and the article author, and then asking it who owns or invests in the news site, who their investors or parent companies are, and so on, and did the same for primary company in the article. Then, I had it make a webpage to show me how they are all connected. Not bad for early ChatGPT.
But why did I care about this? I knew these were investment firms that are invested in pretty much everything. Honestly, I don't know. I just realized I couldn't fully answer this question I had of "Who wants me to know what?" And that question became a quiet obsession.
From Prototype to Release
I started working on this as a side project, and like most side projects, it was given varying degrees
of effort and importance depending on the week. It was also, brutally difficult for me to do. At this
point, I had been a software engineer professionally for about 12 years, and I'd seen a lot. But one I
think I saw rarely, one thing that I absolutely could not stand, coming from my background in .NET, it's
granddad C, and my recent lover of 3 years, Vanilla ES6 Javascript...
was this bullshit:
Seen above: not a single fucking bracket
Fuck this language, I thought. But it's how you AI, so I guess I'll learn it. And
what an emotional roller coaster it was. At this point in my career, I was perfectly
comfortable learning new languages, and did often, but that didn't stop me from thinking that
needing to do shit like this to cover my ass was fucking dumb:
This is one of the few times I'll praise the syntax of Javascript
I know part of the struggle was me just sort of Yoloing the learning of this, but that's how I learn best. And I had my typical pattern of feelings and opinions towards Python as I do learning any language, including JS, which I had just picked up in 2020.
First, I think it's absolutely the stupidest language in the world, then things start to click, then I think it's even worse, and then after a few months of frustration and effort, I start to see the utility of the language; the elegance of the syntax, and frustration turns into a gradual appreciation, and, dare I say, love?
Now, I think Python is amazing. It didn't hurt that I could basically write stuff in C# or JS at this point, and then just give it to ChatGPT and say 'convert this to python', though that had it's own issues that I will probably cover in another post.
In fact, I could easily dedicate a full post to the mistakes that were made when making this
thing, so I won't talk about them in too much detail here, but I will summarize it as follows:
It's working > Local LLMs only > It's too slow > It works on my machine > It's faster
>
"Why not just put it in the cloud?"
yes, I rezzed the original gun emoji to drive home the sheer naivety of this
question
Don't Trust Me, Bro
An important detail nagged at me from that initial prototype - I didn't trust ChatGPT. I didn't trust
the data it was trained on and I didn't trust it's ability to recall it. So it became critical for me to
make every single claim, no matter how small, fully traceable by human beings.
That meant that everything needed a citation, from the evidence of a relationship betwixt two entities, to why the LLM thought that text that referenced "GM" meant "General Motors" and not "Gertrude's Massage."
The more I worked on this, the more obvious that problem became, and I'll likely cover what I learned in another post.
But for now, let's finally get around to how we get from a URL to taking our most statistically accurate guess at the who behind it.
From URL to Who RL 

This process is not just passing a URL, or even a page to an LLM endpoint and giving it a prompt.
Someday it probably will be, but the current process is very structured. The biggest reason for this was
that back in 2023 when I first started working on this, LLMs largely sucked at doing all of this
accurately, so the whole system had a series of classic programming checks, and LLM voting systems in
order to arrive at a correct answer, and, critically, knowing when a stop (a thing LLMs still struggle
with). The strictness of that architecture stuck around, and that allowed for great precision and
efficiency as LLMs improved.
The very first thing we do is identify the news site based on the domain in the URL. This is nice because if we've seen it once, we already know what I have come to call the "ownership tree", which is all of the parent companies and investors influencing this site all the way down the chain.
We then scrape the article, extract the entities, and find their owners or investors, repeating the search until we get to a company that does not produce anything (i.e. has investments, but no products). This is an important distinction to make because many large companies, like Warner Bros. Discovery, invest in things, but still produce products. Likewise, Blackrock and Vanguard invest in each other, and other companies invest in them, so if we just keep looking we wind up mapping the totality of financial exchange throughout the global economy, and this makes the CPU very, very sad.
Once we have a final list of top companies, we compare the ownership trees of the article subject and the news site itself. Often times, where are multiple common owners, at which point, we do additional research to rank the companies by likely capital influence. If there's a tie or we're unable to find that information, the LLM just picks one. You might think it would be helpful to see all of the top owners simultaneously, but even with Pepe's calming UI, doing so becomes nearly unreadable for the current human mind, and if people can't understand the data then the tool is essentially useless.
What's a vegan?
Doing all this in the current version of Pepe mostly involves treating the server as a hub, with calls
to lambda functions which then make their calls to external APIs (scraping, LLM, etc), and then
responding to the server with the result and an ID for the call. The meat of Pepe is divided up into
Jobs, which then start child jobs, and so on. Because of the fan-out nature of this process, it works
best to have as much as possible done on the edge, and then sent back to the server to figure out what
to do next.
Scraping is straightforward, and entity extraction itself is too, but what's not straightforward is knowing which entity to extract. If a news article mentions 7 different companies, shouldn't we just try to find the ownership tree for everything? Well, that is originally what it did, but the results took absolutely forever to get, and they weren't really meaningful to me as a human. So, we need to find out what would be.
That's where our first extraction prompt comes in:
self._system_message = """You are a GROUNDED CORPORATE ENTITY EXTRACTOR.
YOUR ONLY JOB: Extract every company, corporation, or organization that is mentioned or clearly implicated in the article body. Do NOT assess relevance or applicability. Do NOT filter. Just extract.
Return ONLY valid JSON. No markdown, no commentary.
INPUT CONTEXT:
- The article text you receive is SCRAPED MARKDOWN from a web page.
- Scraped markdown often includes boilerplate such as:
- navigation menus
- header/footer links
- newsletter prompts
- related article links
- commerce widgets
- repeated site branding
- You MUST mentally separate probable article content from surrounding boilerplate before extracting.
- Do NOT extract company names that appear ONLY in navigation/boilerplate/footer.
- The article title is a strong signal for the article's actual content.
WHAT COUNTS AS A COMPANY:
- Publicly or privately traded corporations
- Subsidiaries named in the article
- Organizations with commercial operations
- Government agencies ONLY if they are the subject of a financial action (e.g. a contract, fine, or acquisition)
WHAT DOES NOT COUNT:
- Individuals (people are not companies)
- Generic industry references ("tech companies", "automakers")
- Companies mentioned ONLY in boilerplate/nav/footer
- Non-commercial organizations (charities, universities) UNLESS they are the article's primary subject
ERROR ASYMMETRY:
- False negatives are worse than false positives.
- If in doubt whether something is a company, INCLUDE it.
- The downstream system will resolve and disambiguate.
PROMINENCE DEFINITIONS:
- "primary": The article's headline or central narrative is about this company
- "secondary": Significant discussion (multiple paragraphs or a key role in the story)
- "mention": Named once or twice, peripheral to the main story
OUTPUT JSON schema (STRICT):
{
"companies": [
{
"name": "Exact company name as it appears in the article",
"prominence": "primary|secondary|mention",
"context": "One sentence: what role does this company play in the article"
}
]
}
RULES:
- Return ALL companies found in the article body, not just the primary one.
- If no companies are found, return {"companies": []}.
- Do NOT invent companies not present in the article.
- Use the exact name as it appears in the article text.
- Order companies by prominence: primary first, then secondary, then mention.
"""
self._user_message = f"""Extract all companies mentioned in this article.
Respond ONLY with JSON in the exact format specified in the system message.
Article Title:
{title_for_prompt}
Article Text:
{article_text}
"""
A lot of this is purely to keep the LLM on track, and to compensate for past errors it's made. The prompt itself is an evolution of many failed attempts. I've found that rather than asking the LLM for a single company, it yields better results if you ask it to rank them. This happens with other things too, and I think it's a reflection of the 'fuzzy' nature of LLMs and the data they are processing. The goal is to find the signal in the noise, rather than asking for "the answer", and do that from enough directions that you have a clear definition of what you're looking for. Because it keeps the model from inventing things, this also means that (of the models I've used), we will know if the scraped text is a news article about a product or company, or if it's a blog post about someone's dog. This is critical, because we need to know if we're even on the right trail when we get to the next essential stage.
Who Dis?
Now that we have the article subject, we need to identify which company it actually is. We can know the
text says "General Motors", but what does that actually mean? To us, it means the car company, but to a
machine it's just text. Even to an LLM, we can't really be sure what it means because even
though the LLM likely has the company in it's training data, we don't know at what fidelity that
information will be recalled. So, we need to gather evidence. But, even if we search the internet for
General Motors, how do we know we've found the same General Motors, and what context do we even use?
Well, the only reliable context we currently have to anchor the term "General Motors" to the General Motors in the article is the article text itself. We know the article is about General Motors, in some capacity, so we know we can use that text as context during our search.

I thought this section needed to be broken up so here's a preview of the next one
Let's assume it's the first time Pepe is seeing General Motors. That means that we'll try to find the name "General Motors" in our existing database, and it will fail. Then we'll look to see if any entity in the db has an alias of "General Motors" (this is more relevant when the entity found is something like "GM"). After that, we look for existing entities with names like General Motors, and then validate them with an LLM, using the potential matching entity we have and the article context. We do this with a dedicated entity comparison job that is designed to do one thing: determine if the two entities are the same or not, given names and context for each one, and returning true or false with a confidence score.
If we still can't figure it out, we basically do a broad search and send an LLM a bunch of potential existing entities (maybe it's an existing entity with a new name we haven't seen, like Blackrock vs Blackrock, Inc.), along with IDs for each one and have the LLM tell us if one is the same.
If all that still fails, we can be pretty damn sure this is a new entity.
That all might seem like overkill, and it is, until we wind up with fragmented relationships that say Blackrock and Blackrock, Inc. are two separate companies. Despite all the safety checks, this issue exists in production now with some entities, such as "Government of Norway" and "Norwegian State", so we'll need to write a tool and have it do a cleanup pass on the database to merge entities like this.
But at least we have our level best guess at what company this. Now, the question remains: Do we want to try to find out who owns it?
Crème Fraîche
Now, in order to determine if it's worth finding the owners and investors in this company, we need to
know what the company does and what it's known for. Enter the hallowed find_owners_llm.py. This thing is
ridiculous, but it yields valid results.
This is basically going to make double sure we have the entity being passed to us in the database, and then it's going to kick off a series of parallel child jobs that
- Find the parent companies
- Find the investors
- Find the shareholders
All at once with different LLM calls, and then once then aggregating that data via another call once all of those jobs have returned their results.
And even each one of those jobs is required to gather evidence for what it's claiming, with some of them (like the investors job), making separate calls within themselves to prove what they said the first time, and some have other filtering that takes place.
All that gets us to an output data shape that the rest of the investigation can make sense of and that we know is going to be evidence-based and provable. We add each of the companies or investors it found to the same loop of finding owners. We process this loop one 'level' at a time, checking it against the owners of the news site or finding them if we don't have them yet. Which brings us to the final step in the loop, where the magic happens.
Just use this image as the title for this next section
Now, we find out if any of the of the owners or investors of the news site are also owners or investors in our article subject.
This is actually one of the most dirt simple aspects of the whole process. Because we have used the same database as the source of truth for our entity and relationship storage, because every entity has a uuid, and because all of our relationships have a dominant direction (sourceentity always _acts upon targetentity, i.e. _source owns target) we just call a function in our DatabaseService that takes in two entity ids, and checks their parent relationships, recursively, until it runs out of relationships, finds a common owner, or hits a max depth of 50.
If we find a common owner, we consider the investigation 'done', write the final results to supabase (keyed by a normalized url), and we stop the program.
How bow dah?
So, now we have our answer, or at least some piece of it. Why is that important? Why did I do this?
I can't honestly fully say, other that I was curious and I absolutely could not let it go. I think it has something to do with not knowing where information is coming from now but knowing that I could. And something around trying to find a shared narrative at a time when a lack of clarity is becoming increasingly divisive. And true, there may be things we cannot agree on, but we can agree on where our information is coming from, and what incentives might be at play, and I think this is a small step toward getting a fuller picture of that.
Ultimately, I think that democracy thrives when it's participants are well informed, and right now we are over informed. I also think LLMs and adjacent technologies can help us make sense of things we currently don't have time to research ourselves. What would it look like if we could see and make sense of something like bills, lobbyists, political donors, and potential downstream consequences of new laws, all in a simple format, all verified? What if we could do that with geopolitics? I think that kind of thing is inevitable, and it begins by seeing what we can do now.
Brag Section
Before I wrap up, here are some things I'm especially proud of:
- This uses extensive caching so the same entity is never investigated twice, unless we force it to be. That makes it super fast to even parse new articles.
- The way it does a prepass to determine if we even need to run the server, saving us precious fly.io runtime while still giving the user accurate results.
- Cost tracking I built in indicates this is actually cheaper to run than I thought.
- The job system is dope.
- The custom SDF Text Rendering system I wrote for the front end, which can comfortably render over 4 million characters at once on my 8 year old smart phone at 60fps.
- The custom instancing system I wrote for the front end, which has similar performance.
- The url, which inspired the frontend (pepesilv.ai)
- Other wizardry
What's Next?
I want to play with adding support for finding financial links between any two companies (sans news article), see what it's like to track stock prices within networks, and find some ways to monetize this without losing the original reason for building it. Possibly some code cleanup along the way, since this was an evolution in my vibe-coding skill and I think parts of the codebase are reflective of that.
Wrapping Up
Overall, I learned an immense amount doing this project. Mostly around how exactly to make AI do what you want it to do. And if you are trying to get AI to do what you want it to do, I invite you to check out the company I co-founded, Neustac, where we offer custom automation solutions, often with AI in the middle and a human in the loop. You can learn more over at neustac.com.
The next step, of course, is to the render the results in the web, but that's a separate
article. I did go full out with the theme though:
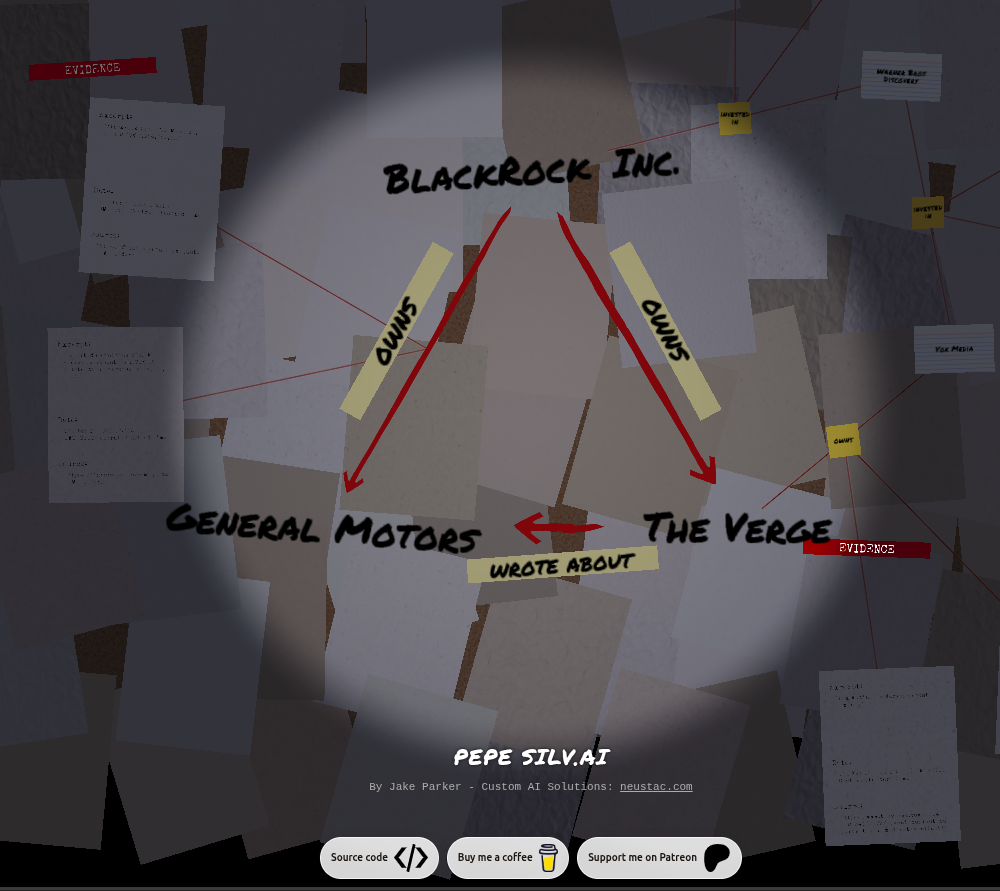
You can find the source code, as well as Coffee and Patreon links below.
Catch ya' later players,
Jake Parker
pepesilv.ai